高级编程语言Python有两个受众:一是编译和执行程序的机器,二是阅读、理解和编写程序的人类。机器关注程序的语义操作,而人类更强调代码的可读性。Python在语法中融入了许多以人类为中心的设计元素,以“可读性至上”为设计原则,因此Python也成为中最受人类欢迎、追捧的编程语言之一。
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
近期,编程语言的受众群体扩展到了LLMs,它们在代码生成、分析甚至执行代码等方面都表现出色。LLMs的角色已经从单纯的代码生成器转变为活跃的“开发者”,可以用来辅助编程并完成各种数学计算和文件处理等复杂任务。这种范式转变标志着LLMs也成为编程语言的重要用户群体。
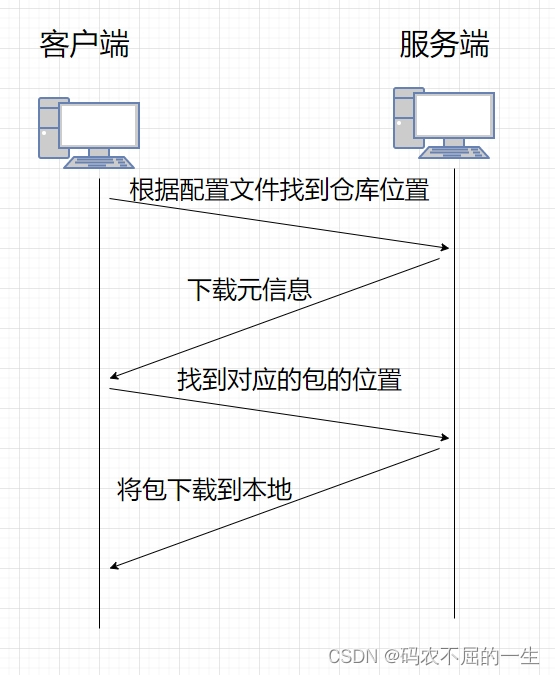
但是我们前面提到的编程语言的“可读性”对于LLMs来说可能并不重要,甚至会带来额外的计算负担。下图是LLMs和人类程序员如何理解源代码的一个示例。
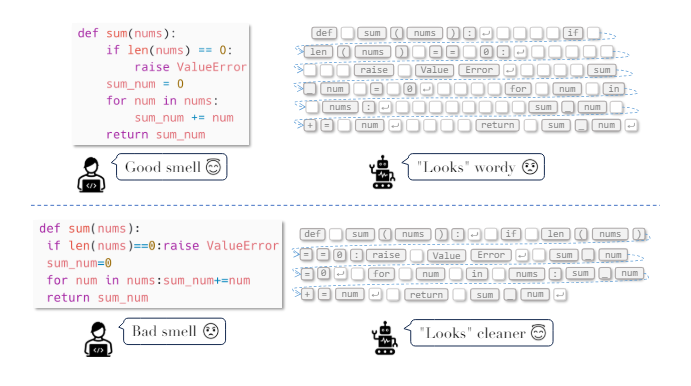
当从代码中省略某些增强可读性的元素比如一些缩进、换行等符号,但保留其底层语义时,人类理解起来会更加困难,但AI模型可以更高效地处理代码。
因此可以减少不必要的tokens输入,从而减少LLMs处理与生成代码时的时间和能源成本。
今天介绍的这篇论文提出了“AI导向语法”的概念,专为AI模型设计的语法。核心思想是提炼出保持代码表示简洁(对AI模型来说,使用最少的tokens)的语法规则。
但是,设计并融入AI导向的新语法到AI模型中面临一系列挑战。这些挑战不仅要求AI模型能够理解并遵循这种新语法编写的代码,还需要它能够基于这种语法高效地生成代码,以满足效率和性能目标。同时,作为指导开发过程的人类开发者来说,他们仍然期望使用一种既友好又熟悉的语法。
为了评估AI导向语法的可行性和实用性,作者进行了一项探索性研究。该研究以三个研究问题为核心,每个问题都旨在深入探讨一个关键挑战:
-
AI导向语法在源代码中能够实现多大程度的tokens缩减?
-
AI模型如何理解面向AI的语法?
-
如何使面向AI的语法支持实际场景?
本文聚焦于Python语言,研究采用了StarcoderData的Python子集,该数据集基于Stack Overflow的庞大代码库,筛选出超过2000万份来自GitHub开源仓库的代码文件。然后进一步筛选出星级超过100的仓库代码文件,最终得到623,887个代码文件。这些文件按照95:5的比例划分为训练集和验证集,以支持模型的训练与验证。在评估模型性能时利用其他已建立的公共数据集进行评估。
论文标题:
AI Coders Are Among Us: Rethinking Programming Language Grammar Towards Efficient Code Generation
论文链接:
https://arxiv.org/pdf/2404.16333
Q1:AI导向语法在源代码中能够实现多大程度的tokens缩减?
为了展示面向AI的语法的潜在优势,作者提出并实现了一个面向AI的Python语法,称为Simple Python(SimPy)作为概念验证。SimPy源于Python的原始语法,但充分简化了语法规则。作者还开发了一个工具包,包括一个用于SimPy源代码解析为Python的抽象语法树(AST)的解析器,以及一个实现SimPy和Python代码的无缝翻译的转换器。
语法设计
SimPy的设计优先考虑AI处理效率而非人类可读性。在分词时,SimPy的代码比Python更紧凑,模型处理更快。下图展示了SimPy和Python代码使用相同的抽象语法树进行比较,可以看出SimPy的tokens数量更少(使用GPT-4的分词器衡量):
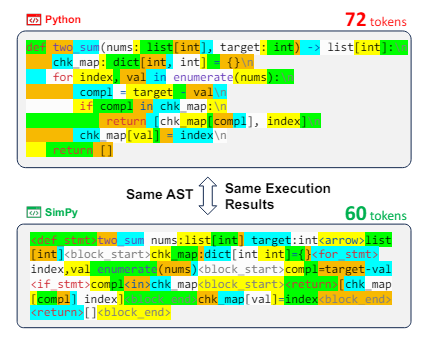
SimPy相比Python语法,主要修改了以下内容:
1. 替换符号为tokens:
在SimPy中,采用了独特的tokens占位符(如“<in>”、“<g>”、“<ge>”)来替代Python中的关键词和大部分符号(如“in”、“>”、“>=”)。这些占位符需被分词器识别为独立token或token的一部分,从而新增了78个tokens。对于明确无歧义且已优化为token的单字符符号(如“.”、“:”、“=”),则保持原样。这种替换不仅简化了分词过程,还消除了对周围空格的需求(如将“a in b”转换为“a<in>b”),区分了不同上下文中使用的相同符号以避免潜在冲突(如“<if_stmt>”与“<if>”),并将Python中的多字符符号合并为单个token以保持其意义的完整性。
2. 限制编码风格:
SimPy极大地简化了Python中的视觉编码风格,它省略了Python中的空格、换行和缩进,转而采用独特的tokens来定义代码结构。在SimPy中,换行符(在Python中用“\n”表示)被替换为专门的token“<line_sep>”,但如果后续行以诸如函数定义的“def”或类定义的“class”等开始,该token则会被省略,从而优化了token的使用。
缩进被两个特定的tokens“<block_start>”和“<block_end>”所替代,它们分别位于代码块的开始和结束处。无论代码块包含多少行,都只需要这两个tokens来表示。此外,SimPy去除了非分隔用的空格和行续字符,进一步简化了语法结构,使其更加紧凑和易于被AI模型处理。
3. 简化语法Tokens
针对SimPy中的生产规则,作者深入分析了每个语法tokens的优化潜力,评估了是否可以通过删除、合并其他tokens,或用空格替换来减少tokens的使用。由于空格在当前的tokenizer中被视为tokens的一部分,这种处理方式能够有效地减少tokens的数量。以下表格展示了关键生产规则在语法规范优化前后的变化,以及由此带来的tokens减少量:

▲表格中的语法token以蓝色表示。'N'表示行数,'n'表示重复元素的数量,'?'表示tokens数量是条件性的。
另外,在全局考虑语法时,某些设计决策可能会引入解析歧义。例如,在Python中,无分隔符连接的字符串如'hello' 'world',在缺少逗号分隔列表元素时(如['1' '2' '3'])会引发混淆。为解决此问题,可采用策略性方法,如在相邻字符串间添加<concat>,以消除歧义,尽管会增加tokens数量,但对SimPy整体效率仍有益。
SimPy的无歧义性
验证SimPy语法的无歧义性至关重要,本文通过tree-sitter中的GLR(广义从左至右最右推导解析器)为其生成了解析器,并在测试过程中未检测到任何歧义。
为何这种转换不太可能引入语法歧义?原因在于转换仅针对终端符号进行,这些符号包括关键字和分隔符。对关键字的修改确保了其独特的语义不会与其他符号混淆,而对分隔符的修改也不会影响语法结构的识别,从而保证了语法的清晰性和无歧义性。
SimPy和Python之间的语义等价
SimPy 被设计为Python的简化语法,这意味着用Python编写的程序可以等价且确定地转换为其在SimPy 中的对应版本,反之亦然。作者对此做了详细证明,因篇幅所限,此处不再赘述。
实验设置与分析
工具包开发
作者为SimPy开发了一个全面的工具包,包括一个基于tree-sitter的解析器和一个转换器,用于在SimPy和Python源代码之间实现无缝转换。首先,在tree-sitter的配置文件中定义了SimPy的语法规则,并利用其GLR(广义从左至右最右推导)算法生成了相应的解析器。GLR算法确保了SimPy能够解决所有潜在的语法冲突,从而消除了歧义。生成的解析器能够将SimPy源代码准确地解析为Python的抽象语法树(AST)。接下来,为AST的每个节点制定了详细的转换规则,并实现了转换器。这一步骤确保了SimPy代码与Python代码之间的准确转换。
评估实验
作者将Python数据集在原始语法和SimPy语法下分别表示,并用相同的分词器进行分词。通过转换器,将Python数据集转换为SimPy数据集,并调整了分词器的词汇表以包含SimPy的tokens。实验涵盖了14个来自流行LLMs的分词器,记录了其词汇来源和大小,以全面评估SimPy在不同模型上的性能。结果如下表所示:
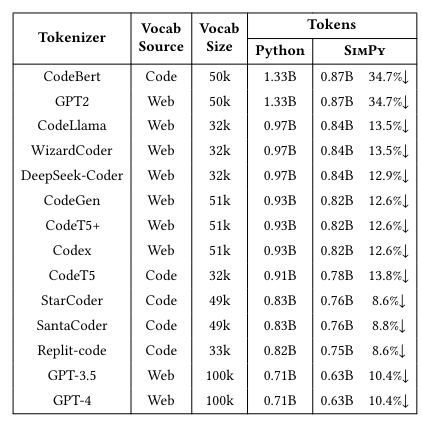
SimPy显著减少了tokens数量,降幅在8.6%至34.7%之间,具体取决于所使用的分词器。GPT-4和GPT-3.5等高效分词器在表示Python源代码时,通过SimPy进一步减少了10.4%。基于代码语料库训练的分词器(如Replit-code和StarCoder)实现了8.6%至13.8%的减少。而基于网络语料库的分词器(如CodeGen和CodeT)也减少了12.6%至13.5%。对于效率较低的CodeBert和GPT-2分词器,SimPy带来了高达34.7%的tokens数量减少。
这些结果表明SimPy在降低源代码表示的tokens数量方面具有巨大潜力,进而减少浮点运算加速推理速度。
综上,可以很好的回答Q1的问题"AI导向语法在源代码中能够实现多大程度的tokens缩减?""
以SimPy为例,面向AI的语法设计显著减少了源代码表示所需的tokens数量,特别是对于像GPT-4这样的模型,其tokens数量减少了10.4%。这种减少在推理过程中直接转化为速度的提升和计算资源的节省,进一步提升了AI模型在处理源代码时的效率和性能。
Q2:AI模型如何理解面向AI的语法?
训练策略
Tokenizer 优化
SimPy引入了78个新tokens供tokenizer识别,比如原Python语法的"def"关键字被新token "def_stmt>"所替代。鉴于预训练模型和tokenizer的现有关系,全面重训tokenizer以优化tokens分布并不实际。因此,采取扩展tokenizer原有词汇表,纳入新tokens的方法。
这一变更要求调整嵌入矩阵(词汇表大小乘以嵌入大小)和输出层(隐藏状态大小乘以词汇表大小),以适应词汇表的扩大。同时,每个新token的嵌入向量和输出层权重将被随机初始化,并在模型训练过程中更新。
模型训练
本文对比了两种训练策略以探索AI导向语法的有效性。一是直接在SimPy代码数据集上训练模型(称为SimPy);二是先在Python数据集上预训练,再在SimPy代码数据集上微调(称为Python→SimPy)。同时设立了对照组,即在Python代码数据集上直接训练模型(称为Python)。
为保持一致性,所有策略和对照组的训练条件均相同,涵盖训练环境、初始模型和超参数设置。此外,SimPy数据集基于Python数据集转换而来,确保无外部数据干扰。对于Python+SimPy策略,评估了不同SimPy数据集使用比例(10%、20%、50%和100%)下的微调效果。
实验设置
模型选用与评价指标
本文采用了社区广泛使用的三个模型,即CodeGen-NL、TinyLlama和Pythia作为实验的初始预训练模型。
使用Pass@𝑘指标评估模型在代码生成任务上的性能,该指标HumanEval上进行计算。HumanEval数据集由OpenAI开发,包含164个编程问题,每个问题都有函数签名、文档字符串和多个测试用例。模型需要根据函数签名和文档字符串生成代码,然后通过执行测试用例来检验代码。
实验结果
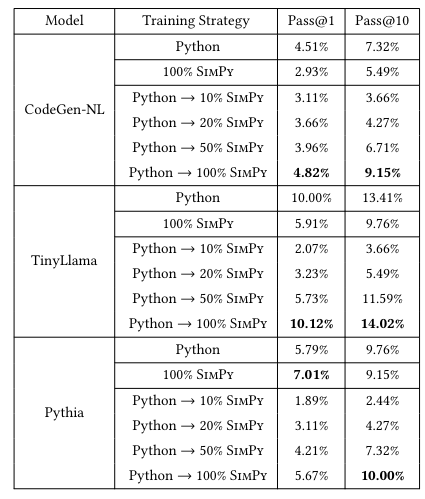
对于每个初始模型,得到六个变体:Python 和 SimPy 各一个,以及 Python→SimPy 中包含 10%、20%、50% 和 100% SimPy数据集的四种模型。结果如下表所示:
-
使用100% SimPy数据训练的模型在准确性上不及Python基准,例如CodeGen (SimPy)的Pass@1和Pass@10分别为2.93%和5.49%,明显低于CodeGen (Python)的4.51%和7.32%。这可能是由于SimPy的表达能力受限,导致模型在预训练阶段无法充分从自然语言数据集中学习。因此,直接使用面向AI的SimPy语法进行训练似乎并非有效方法。
-
先在Python数据集上预训练,再在SimPy代码数据集上微调的策略(Python→SimPy)是可行的。比如使用Python→100%SimPy 训练的CodeGen-NL、TinyLlama 和 Pythia 模型的 Pass@10 分别达到 9.15%、14.02% 和 10.00%,优于仅使用Python预训练的方法。有趣的是,当 Pythia 模型仅使用 100% SimPy 进行训练时,其Pass@1 甚至超过了 Python 基准。这表明学习 SimPy不一定需要顺序训练策略。
-
通过调整 Python→SimPy 设置中 SimPy 数据集的比例,发现使用 SimPy 进行微调仍然需要大量的数据。例如,TinyLlama (Python→50% SimPy) 的Pass@1 和 Pass@10 分别为 5.73% 和 11.59%,仍然落后于 TinyLlama (Python) 的成绩。
通过实验,可以很好的回答本节一开始的问题:“AI模型如何理解面向AI的语法?”
通过AI模型先在原始语法上进行预训练然后使用面向AI的语法进行微调的方法,AI模型可以成功地学习面向AI的语法,保持甚至提高其准确性。
Q3:如何让面向AI的语法规则支持实际场景?
基本使用场景
当使用面向AI的语法编写源代码时,人类理解起来会变得困难,因此并不适合人类查看。面向AI的语法的应用主要限于人类用户无法接触到生成代码的场景。比如在AutoGPT和LangChain等agents中,人类用户只需要关注结果而不用理解底层脚本,如下图左侧图示。
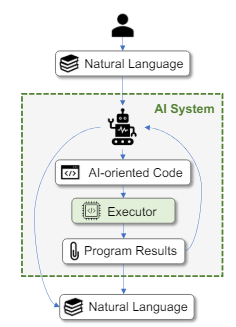
在这种情况下,模型生成的面向AI的代码可以通过以下两种方式执行:1)将其翻译成人类可读的代码,再由标准的执行器执行;2)直接由专为面向AI语法设计的特定执行器执行。而第二种方法通常更为高效、轻量,因为面向AI的代码在结构上往往更为简洁和一致,更易于解析和执行。
扩展的使用场景
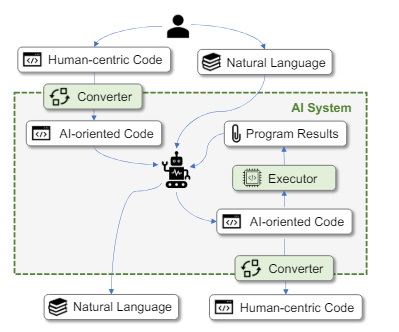
尽管AI导向的语法在某些场景下展现出显著优势,但在众多需要人类介入的代码生成场景中,人类可读的代码仍然是不可或缺的。为此,作者提出了DualCode的代码生成推理框架。
DualCode旨在让用户能够使用以人类为中心的语法与代码进行交互,同时在推理过程中充分利用AI导向语法的效率。DualCode的核心功能在于实现代码在AI导向语法与目标编程语言原始语法之间的双向转换。
下图展示了DualCode的工作流程,它包含两个“门”:输入转换器和输出转换器。输入转换器将人类为中心的语法编写的代码转换为AI导向语法供模型处理。类似地,输出转换器将AI生成的代码转换回人类可读的形式以供用户理解。这个环境仅针对代码,自然语言等其他输入不受影响。
实验结果
鉴于DualCode转换器可能增加推理延迟,本文测量了Python代码文件转换为SimPy再转回Python的时间,并与于广为人知的Huggingface Tokenizers库的StarCoder分词器处理速度进行对比。将代码文件按tokens计数分为五组:(0, 100),[100, 500),[500, 2000),[2000, 5000),及[5000, +∞),这些计数是使用StarCoder确定的。计算了各组的平均处理时间,以评估转换器性能。结果如下表所示:
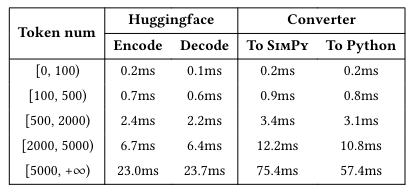
实验结果表明,DualCode转换器的速度与Huggingface Tokenizers相当。鉴于实际数据集中超过95%的代码文件(来自真实仓库)的tokens都在5000个以内,因此转换器在实际应用中引起的延迟是可接受的,对系统性能的影响较小。
综上,对于问题“如何让面向AI的语法规则支持实际场景?”的结论如下:
除了无需人类交互的基本场景外,通过整合DualCode框架,面向AI的语法应用可以得到充分扩展。当tokens数量在500以内时,延迟低于1毫秒,几乎可以忽略不计。
结论
本论文首次提出了面向AI的语法概念,旨在解决AI编码器处理以人类为中心语法时的效率问题。通过一项基于三个研究问题的实证研究,验证了这一新颖概念的可行性和潜力。研究过程中,开发了首个面向AI的Python语法,并引入了一个推理框架,使模型能够高效处理编程语言中的AI导向语法和人类中心语法。作为新兴领域,AI导向语法还有许多问题有待进一步探索。